Optimizando Consultas
Módulo 3: Entendiendo los Planes de Ejecución
Nuestra Misión en este Módulo
- El Problema: ¿Por qué nuestras consultas se vuelven lentas?
- El Diagnóstico: Entender el "cerebro" de Spark y su plan de ataque.
- Las Soluciones: Aplicar optimizaciones a nivel de directorios, archivos y algoritmos.
- El Mantenimiento: Asegurar que el rendimiento se mantenga en el tiempo.
El Enemigo: El "Full Table Scan"
A medida que nuestros datos crecen, las consultas simples se ralentizan. La causa principal es que, por defecto, Spark se ve obligado a leer **cada fila y cada columna** de una tabla para encontrar lo que busca.
Nuestro objetivo es darle a Spark la información que necesita para evitar este trabajo innecesario.
El Diagnóstico: `EXPLAIN`
Antes de optimizar, debemos diagnosticar. El comando `EXPLAIN` es nuestra herramienta de Rayos X: nos muestra el **Plan de Ejecución** que Spark ha decidido seguir, sin ejecutar la consulta.
No miramos el plan para ver el código, sino para buscar **pistas** sobre el comportamiento de Spark, como por ejemplo:
- ¿Está leyendo toda la tabla?
- ¿Está usando nuestras particiones?
- ¿Qué estrategia de JOIN ha elegido?
El Cerebro: Optimizador Catalyst
Una consulta pasa por un complejo proceso de optimización antes de ejecutarse. Catalyst la transforma de una simple idea a un plan de ataque altamente eficiente.
Solución Nivel 1: Optimización a Nivel de Directorios
Particionamiento
¿Qué es el Particionamiento?
Es como organizar un archivador gigante en cajones separados por fecha. En lugar de buscar en todo el archivador, vas directamente al cajón correcto.
Directory Skipping (Salto de Directorios)
Cuando filtramos por la columna de partición (ej. `WHERE id_fecha = '2023-01-15'`), Spark ignora físicamente todos los demás directorios. La prueba en el plan `EXPLAIN` es la presencia de **`PartitionFilters`**.
Solución Nivel 2: Optimización a Nivel de Archivos
Z-Ordering
¿Qué es el Z-Ordering?
Continuando la analogía: una vez que abrimos el cajón correcto (la partición), el Z-Ordering es como tener los documentos adentro perfectamente ordenados por cliente.
File Skipping (Salto de Archivos)
Spark utiliza las estadísticas (min/max) de cada archivo para saber si necesita abrirlo. Al filtrar por `id_usuario`, puede ignorar la mayoría de los archivos dentro de una partición, reduciendo drásticamente la lectura.
Solución Nivel 3: Optimización de Algoritmos
Estrategias de JOIN
El Arte de Conectar Datos
El Director de Orquesta: AQE
La **Ejecución Adaptativa de Consultas (AQE)** es la capacidad de Spark para cambiar su estrategia de JOIN a mitad de la ejecución si los datos reales no coinciden con sus estimaciones, garantizando casi siempre el plan más óptimo.
Vemos su presencia en el plan con el operador `AdaptiveSparkPlan`.
El Mantenimiento: Mantener la Velocidad
Las optimizaciones no son estáticas. Para que Spark siga tomando buenas decisiones, debemos mantener nuestras tablas.
`OPTIMIZE`
Es como "ordenar y limpiar" nuestro archivador. Compacta archivos pequeños y aplica el Z-Ordering.
`ANALYZE TABLE`
Es como "hacer un inventario". Recolecta estadísticas para que Spark sepa el tamaño y la distribución de los datos.
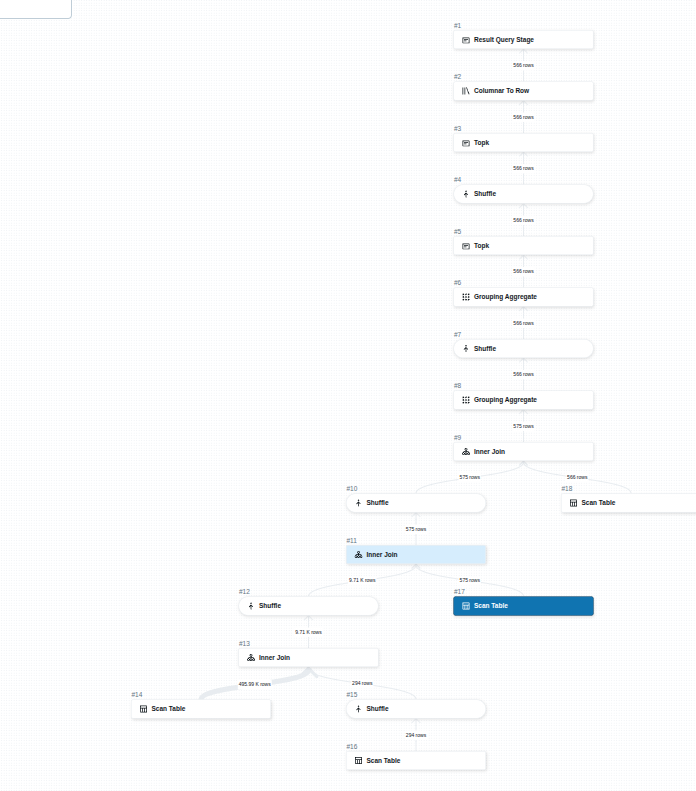
Anatomía de una Consulta Real
El plan de ejecución para nuestro ejercicio final es un mapa perfecto de todo lo que hemos aprendido.

Desglosando el Plan:
- Múltiples Scans: La base del plan (#14, #16, #17, #18) es leer las 4 tablas. Aquí es donde el Particionamiento y Z-Ordering hacen su magia para reducir el I/O.
- Shuffles y Joins: Vemos una cascada de Joins (#13, #11, #9) para combinar los datos. Cada uno requiere un costoso Shuffle para co-localizar las claves.
- Agregación: Los nodos `Grouping Aggregate` (#8, #6) realizan el `COUNT(*)` y el `GROUP BY`.
- Orden y Límite: Finalmente, los nodos `TopK` (#5, #3) ordenan los resultados y seleccionan los 5 mejores, cumpliendo con el `ORDER BY` y `LIMIT`.
Resumen del Módulo
- El rendimiento no es magia, es **diseño y mantenimiento**.
- Usamos **`EXPLAIN`** para diagnosticar y verificar, no para adivinar.
- Optimizamos en capas: **Particionamiento** (directorios), **Z-Ordering** (archivos) y **Estrategias de JOIN** (algoritmos).
- **AQE** es nuestra red de seguridad, adaptándose a la realidad de los datos.
- Mantener las **estadísticas actualizadas** con `ANALYZE` es crucial.
¡Gracias!
Preguntas y Siguientes Pasos