Introducción: ¿Por qué necesitamos un mapa?
De la idea al valor: Navegando la complejidad de los proyectos de datos.
El Problema: El Laberinto de la Experimentación
Los proyectos de datos son como icebergs: la parte emocionante (el modelo) es solo el 10%. El 90% restante es un viaje complejo y arriesgado bajo la superficie.
Objetivos Difusos
Síntoma: El equipo produce análisis y visualizaciones, pero nadie en negocio sabe cómo usarlos para tomar decisiones.
Causa: Falta de una fase inicial para traducir un problema de negocio en una pregunta de datos específica.
Resultados Irrepetibles
Síntoma: Un resultado crucial obtenido hace un mes no puede ser recreado hoy.
Causa: No se versionaron los datos, el código o el entorno exacto, haciendo la reproducibilidad una cuestión de suerte.
Colaboración Rota
Síntoma: El proyecto depende de una sola persona y su portátil. Si se va, el conocimiento se va con ella.
Causa: Falta de un repositorio central y un flujo de trabajo estándar que permita a varios miembros contribuir y revisar.
El Valle de la Muerte del ML
Síntoma: Se celebra el accuracy del 98% en un Jupyter Notebook, pero el modelo nunca impacta al cliente.
Causa: No existe un puente (pipeline) entre la experimentación y la operación (producción).
Anatomía de un Proyecto Fallido
Semana 1: El Despegue
Gran entusiasmo. Se encuentra un dataset "interesante" y se inicia un notebook para "explorar". El objetivo es vago: "encontrar insights".
Semana 4: La Complejidad
El notebook ya tiene 300 celdas. Hay celdas que no se pueden ejecutar en orden. Se crean copias locales del dataset con "pequeños arreglos".
Semana 8: El Primer Muro
Negocio pide una demo. El notebook es demasiado lento y frágil para mostrarlo en vivo. Se intenta "limpiar" el código, creando `analysis_final_v2.ipynb`.
Semana 12: La Pérdida
El científico de datos original es reasignado. Nadie se atreve a tocar su código. El proyecto queda en un limbo técnico.
Semana 16: El Abandono
El proyecto se declara en "pausa indefinida" y se archiva en una carpeta compartida. Una gran idea muere por falta de estructura.
Del Caos a la Claridad: Un Antes y un Después
ANTES: El Flujo del Notebook Aislado
DESPUÉS: El Ciclo de Vida Estructurado
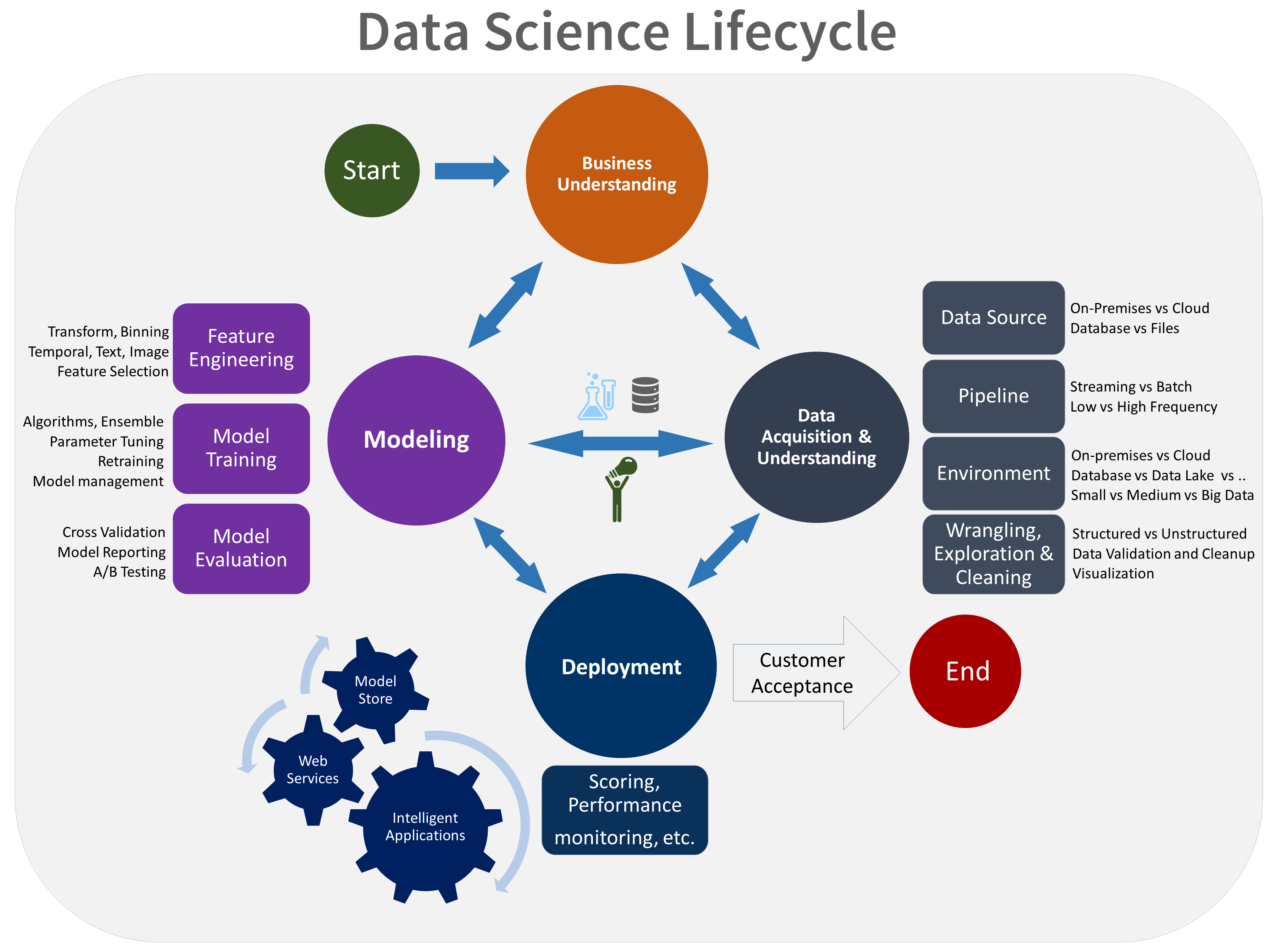
La Solución: Una Metodología es tu Mapa
Un marco de trabajo no limita la creatividad; la canaliza. Transforma un esfuerzo artesanal en un proceso de ingeniería repetible y escalable.
Predictibilidad
En lugar de un camino incierto, tienes un mapa con fases claras (ej. Entendimiento del Negocio, Preparación de Datos). Esto permite estimar tiempos, asignar recursos y gestionar las expectativas de los stakeholders.
Reproducibilidad
Deja de ser un arte oscuro. Un proceso estándar, apoyado por herramientas como Git, garantiza que cualquier resultado pueda ser auditado y recreado. La confianza en los resultados aumenta exponencialmente.
Colaboración
Establece un lenguaje y un proceso comunes. Un ingeniero de datos, un científico de datos y un analista de negocio pueden colaborar eficientemente porque todos entienden en qué fase está el proyecto y cuál es el siguiente paso.
Alineación con MLOps
Una metodología es el **plano arquitectónico (el "qué")**. MLOps es la **maquinaria de construcción (el "cómo" automatizado)**. No puedes construir una fábrica de modelos de ML sin un plano claro de lo que quieres producir.
El Verdadero Modelo Productivo: ¡Este es el Mapa!
Observa este ciclo de vida de AWS. No es una línea recta, es un ciclo continuo que va desde el objetivo de negocio hasta el monitoreo en producción. Este es el mapa que te guía para construir productos de datos robustos, no solo scripts. Pasa el cursor sobre las áreas para explorarlas.
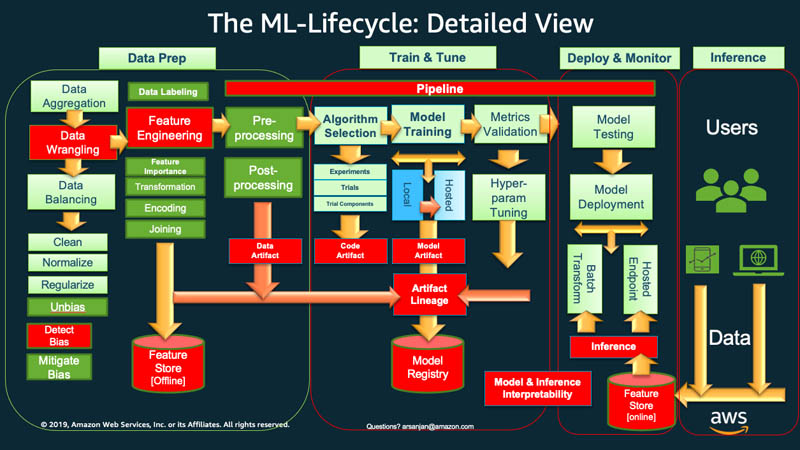
Explorando los Marcos de Trabajo
No existe una única ruta correcta. Cada metodología ofrece una perspectiva diferente. Conozcamos las más importantes para que puedas elegir la que mejor se adapte a tu equipo y proyecto.
CRISP-DM (Cross-Industry Standard Process for Data Mining)
Origen: Creada en los 90 por un consorcio de empresas (incluyendo SPSS, Teradata, Daimler AG).
Filosofía: Centrada en el negocio. Es la más popular por su flexibilidad y su fuerte énfasis en entender el problema de negocio antes de tocar cualquier dato. El ciclo de vida no es lineal, permitiendo volver a fases anteriores si es necesario.
- Comprensión del Negocio: Definir objetivos y requisitos.
- Comprensión de los Datos: Recolectar y explorar datos iniciales.
- Preparación de los Datos: Limpiar, formatear y crear nuevas variables (feature engineering).
- Modelado: Seleccionar técnicas y entrenar modelos.
- Evaluación: Validar que el modelo cumple los objetivos de negocio.
- Despliegue: Integrar el modelo en los sistemas de producción.

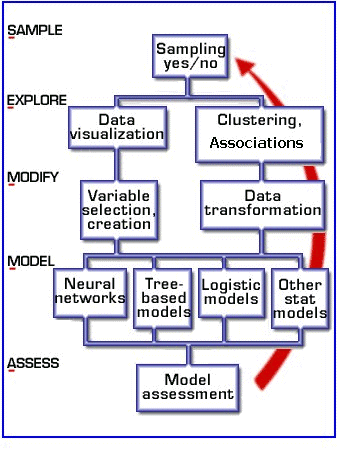
SEMMA (Sample, Explore, Modify, Model, Assess)
Origen: Desarrollada por el SAS Institute.
Filosofía: Centrada en las herramientas y el proceso técnico. Es más una lista de pasos secuenciales que un ciclo completo. Implícitamente asume que los objetivos de negocio ya están definidos y se enfoca en la ejecución del modelado.
- Sample (Muestrear): Extraer un subconjunto de datos lo suficientemente grande y representativo.
- Explore (Explorar): Visualizar y entender las relaciones entre las variables.
- Modify (Modificar): Transformar y seleccionar las variables más importantes.
- Model (Modelar): Aplicar algoritmos de modelado.
- Assess (Evaluar): Comparar los modelos y evaluar su utilidad técnica.
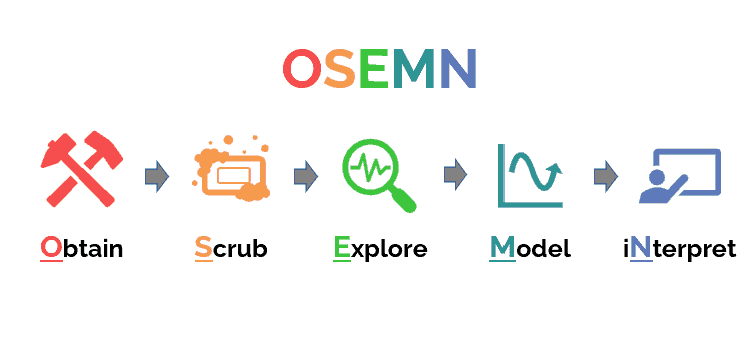
OSEMN (Obtain, Scrub, Explore, Model, iNterpret)
Origen: Popularizada en la comunidad de data science como un "checklist" práctico.
Filosofía: Centrada en las tareas del científico de datos. Es menos una metodología formal y más un resumen del flujo de trabajo diario de un analista o científico de datos, ideal para proyectos de análisis exploratorio.
- Obtain (Obtener): Conseguir los datos (vía SQL, APIs, web scraping, etc.).
- Scrub (Limpiar): Procesar datos faltantes, outliers, formateo. Es la parte "sucia" del trabajo.
- Explore (Explorar): Análisis exploratorio de datos (EDA), encontrar patrones y visualizar.
- Model (Modelar): Construir el modelo predictivo o descriptivo.
- iNterpret (Interpretar): Explicar los resultados del modelo y comunicar el valor de negocio.
TDSP (Team Data Science Process)
Origen: Creada por Microsoft.
Filosofía: Centrada en la agilidad, la colaboración en equipo y el ciclo de vida en la nube (especialmente Azure). Es la más prescriptiva y moderna, proporcionando plantillas y una estructura de repositorio estandarizada.
- Ciclo de Vida: Similar a CRISP-DM, pero con un enfoque iterativo y ágil.
- Estructura de Proyecto Estandarizada: Define una estructura de directorios y plantillas de documentos.
- Infraestructura y Recursos: Hace hincapié en el uso de herramientas en la nube.
- Herramientas y Utilitarios: Promueve el uso de control de versiones (Git) y seguimiento de trabajo (Agile/Scrum).
Análisis Comparativo: ¿Cuál es mi Ruta Ideal?
La mejor metodología es la que tu equipo realmente usa. Aquí tienes una guía para decidir cuál se ajusta mejor a tus necesidades.
| Criterio | CRISP-DM | SEMMA | OSEMN | TDSP |
|---|---|---|---|---|
| Enfoque Principal | Negocio y Proceso | Técnico y Herramientas | Tareas del Científico de Datos | Equipo, Agilidad y Cloud |
| Flexibilidad | Muy Alta (Cíclica) | Media (Más Secuencial) | Alta (Checklist) | Baja (Muy Prescriptiva) |
| Fase de Negocio | Explícita y Fundamental | Implícita (Se asume) | Implícita en "Interpretar" | Explícita y Central |
| Despliegue | Fase final explícita | No lo cubre | No lo cubre | Fase final explícita |
CRISP-DM
Úsalo cuando: El problema de negocio es complejo y requiere una profunda alineación con los stakeholders. Es ideal para proyectos estratégicos donde el "porqué" es tan importante como el "cómo". Su naturaleza cíclica es perfecta para la exploración y el descubrimiento.
SEMMA
Úsalo cuando: El objetivo de negocio ya está claro y el equipo necesita un flujo de trabajo técnico guiado. Funciona bien en entornos donde se utiliza un stack de herramientas específico (como el ecosistema SAS) y el enfoque es puramente en el modelado.
OSEMN
Úsalo cuando: Realizas análisis exploratorios, proyectos individuales o necesitas un checklist rápido y práctico. Es el "mapa de bolsillo" del científico de datos para una tarea específica, más que para la gestión de un proyecto a gran escala.
TDSP
Úsalo cuando: Trabajas en un equipo grande, en un entorno cloud (especialmente Azure), y la estandarización, reproducibilidad y agilidad son críticas. Es la opción más robusta para equipos que quieren implementar MLOps de manera formal.
Fuentes y Referencias
Las estadísticas y metodologías presentadas se basan en reportes y artículos reconocidos en la industria.
VentureBeat (2019)
Estadística del 87%: Proviene de su artículo que destacó la brecha entre la experimentación y la producción en IA, una cifra que se ha vuelto un estándar en la industria de MLOps.
Forbes & Anaconda
Estadística del 80%: La "regla 80/20" de la preparación de datos ha sido validada en múltiples encuestas, incluyendo el reporte "State of Data Science" de Anaconda.
Google, IBM & Microsoft
Degradación del Modelo (Drift): Investigaciones de estos líderes tecnológicos confirman el "model drift" como una de las principales y más comunes causas de fallo de modelos en producción.