Visualización de datos con Python#
Nuevamente cargamos el dataset de ifood para hacer una exploración de los datos. Para este caso, vamos a hacer una exploración de los datos desde las medidas de tendencia central y dispersión. Así mismo, vamos a hacer una exploración de los datos categóricos que aquí se encuentran escritos como variables dummy.
Carga de datos#
Recordemos que para cargar los datos debe hacer clic en el panel izquierdo en el botón de exploración de archivos. En ese menu tendra la opción de subir algunos datos.
Note
Recuerde que para cargar los datos debe hacer clic en el panel izquierdo en el botón de exploración de archivos. En ese menu tendra la opción de subir algunos datos. En Google Colab, el archivo se borrará una vez que se cierre el entorno.
import pandas as pd
# Load the dataset from the user's Google Drive
df = pd.read_csv("ifood_df.csv")
# Show DataFrame
df.head(5)
| Income | Kidhome | Teenhome | Recency | MntWines | MntFruits | MntMeatProducts | MntFishProducts | MntSweetProducts | MntGoldProds | ... | marital_Together | marital_Widow | education_2n Cycle | education_Basic | education_Graduation | education_Master | education_PhD | MntTotal | MntRegularProds | AcceptedCmpOverall | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 58138.0 | 0 | 0 | 58 | 635 | 88 | 546 | 172 | 88 | 88 | ... | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 1529 | 1441 | 0 |
| 1 | 46344.0 | 1 | 1 | 38 | 11 | 1 | 6 | 2 | 1 | 6 | ... | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 21 | 15 | 0 |
| 2 | 71613.0 | 0 | 0 | 26 | 426 | 49 | 127 | 111 | 21 | 42 | ... | 1 | 0 | 0 | 0 | 1 | 0 | 0 | 734 | 692 | 0 |
| 3 | 26646.0 | 1 | 0 | 26 | 11 | 4 | 20 | 10 | 3 | 5 | ... | 1 | 0 | 0 | 0 | 1 | 0 | 0 | 48 | 43 | 0 |
| 4 | 58293.0 | 1 | 0 | 94 | 173 | 43 | 118 | 46 | 27 | 15 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 407 | 392 | 0 |
5 rows × 39 columns
import pandas as pd
# Load the dataset from the user's Google Drive
df = pd.read_csv("ifood_df.csv")
# Show DataFrame
df.head(5)
| Income | Kidhome | Teenhome | Recency | MntWines | MntFruits | MntMeatProducts | MntFishProducts | MntSweetProducts | MntGoldProds | ... | marital_Together | marital_Widow | education_2n Cycle | education_Basic | education_Graduation | education_Master | education_PhD | MntTotal | MntRegularProds | AcceptedCmpOverall | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 58138.0 | 0 | 0 | 58 | 635 | 88 | 546 | 172 | 88 | 88 | ... | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 1529 | 1441 | 0 |
| 1 | 46344.0 | 1 | 1 | 38 | 11 | 1 | 6 | 2 | 1 | 6 | ... | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 21 | 15 | 0 |
| 2 | 71613.0 | 0 | 0 | 26 | 426 | 49 | 127 | 111 | 21 | 42 | ... | 1 | 0 | 0 | 0 | 1 | 0 | 0 | 734 | 692 | 0 |
| 3 | 26646.0 | 1 | 0 | 26 | 11 | 4 | 20 | 10 | 3 | 5 | ... | 1 | 0 | 0 | 0 | 1 | 0 | 0 | 48 | 43 | 0 |
| 4 | 58293.0 | 1 | 0 | 94 | 173 | 43 | 118 | 46 | 27 | 15 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 407 | 392 | 0 |
5 rows × 39 columns
Visualización de datos#
La visualización de datos es una parte fundamental en el análisis de datos. Los gráficos nos permiten comprender y comunicar de manera efectiva la información contenida en los datos.
En este notebook, utilizaremos las siguientes bibliotecas para crear gráficos:
Matplotlib: una biblioteca de trazado de gráficos en 2D que produce figuras de calidad de publicación en una variedad de formatos impresos y entornos interactivos en todas las plataformas.
Seaborn: una biblioteca de visualización de datos basada en Matplotlib que proporciona una interfaz de alto nivel para dibujar gráficos estadísticos atractivos y informativos.
Plotly: una biblioteca de visualización interactiva que permite crear gráficos interactivos y personalizables.
Note
Las librerias son modulos de python que contienen funciones y objetos que pueden ser utilizados para realizar tareas específicas. En este caso, las librerias matplotlib, seaborn y plotly son librerias de visualización de datos. Recuerda que ya hemos cargado pandas y numpy. Cada vez que se inicializa el entorno de ejecución, es necesario volver a cargar las librerias y deben incluirse todas las librerias que se van a utilizar en el notebook.
Gráficos de datos numéricos#
Vamos a hacer una exploración de los datos numéricos que se encuentran en el dataset. Para ello, vamos a hacer un análisis de las medidas de tendencia central y dispersión. Así mismo, vamos a hacer un análisis de la distribución de los datos.
Note
Recuerda que los datos numéricos son aquellos que se pueden sumar, restar, multiplicar o dividir. En este caso, vamos a hacer un análisis de las variables numéricas que se encuentran en el dataset.
import matplotlib.pyplot as plt
import seaborn as sns
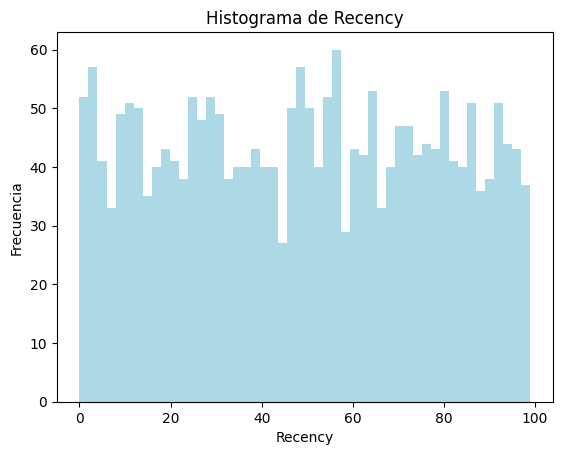
## Gráficos para la variable 'Recency'
# Histograma
plt.hist(df['Recency'], bins=50, color='lightblue')
plt.xlabel('Recency')
plt.ylabel('Frecuencia')
plt.title('Histograma de Recency')
plt.show()
Note
El comando bins es utilizado para definir el número de intervalos en los que se va a dividir el histograma.
Ejercicio
Realiza un análisis de las variables numéricas que se encuentran en el dataset. ¿Como se interpreta el gráfico si se modifica varias veces el comando bins?
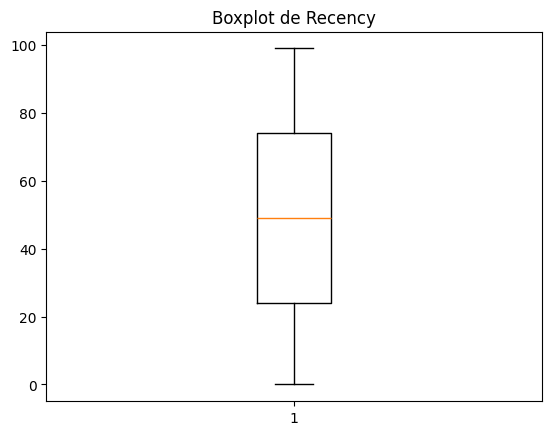
### Boxplot
plt.boxplot(df['Recency'])
plt.title('Boxplot de Recency')
plt.show()
Ejercicio
¿Cómo se interpreta el gráfico boxplot? ¿Qué información nos da este gráfico?
Gráficos para dos variables#
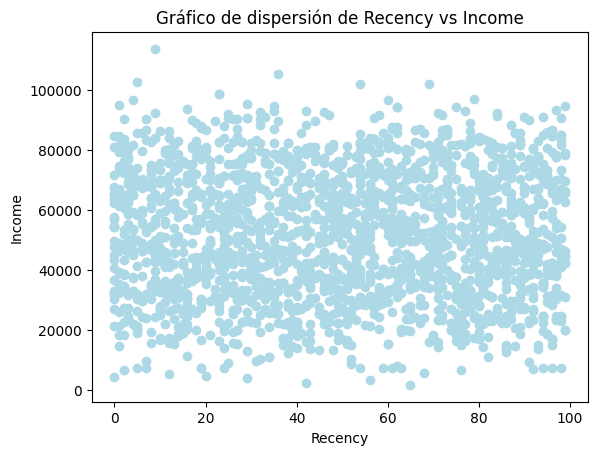
En el caso de las variables que tenemos en el dataset, resultaría interesante ver la relación entre ‘Recency’ y ‘Income’. Para ello, vamos a hacer un gráfico de dispersión.
Note
El gráfico de dispersión es un gráfico que utiliza coordenadas cartesianas para mostrar los valores de dos variables para un conjunto de datos. Los datos se muestran como una colección de puntos, cada uno con el valor de una variable que determina la posición en el eje horizontal y el valor de la otra variable que determina la posición en el eje vertical.
Ejercicio
Realiza un gráfico de dispersión entre las variables ‘Recency’ e ‘Income’. ¿Qué relación observas entre estas dos variables?
### Gráfico de dispersión
plt.scatter(df['Recency'], df['Income'], color='lightblue')
plt.xlabel('Recency')
plt.ylabel('Income')
plt.title('Gráfico de dispersión de Recency vs Income')
plt.show()
Gráficos para variables categóricas#
En este dataset no hay variables categoricas, pero vamos a hacer un análisis de las variables dummy que se encuentran en el dataset.
Note
Las variables dummy son variables que toman el valor de 0 o 1 para indicar la presencia o ausencia de una categoría.
Ejercicio
¿Cuáles son las variables dummy que se encuentran en el dataset? Realiza un análisis de estas variables.
df.columns
Index(['Income', 'Kidhome', 'Teenhome', 'Recency', 'MntWines', 'MntFruits',
'MntMeatProducts', 'MntFishProducts', 'MntSweetProducts',
'MntGoldProds', 'NumDealsPurchases', 'NumWebPurchases',
'NumCatalogPurchases', 'NumStorePurchases', 'NumWebVisitsMonth',
'AcceptedCmp3', 'AcceptedCmp4', 'AcceptedCmp5', 'AcceptedCmp1',
'AcceptedCmp2', 'Complain', 'Z_CostContact', 'Z_Revenue', 'Response',
'Age', 'Customer_Days', 'marital_Divorced', 'marital_Married',
'marital_Single', 'marital_Together', 'marital_Widow',
'education_2n Cycle', 'education_Basic', 'education_Graduation',
'education_Master', 'education_PhD', 'MntTotal', 'MntRegularProds',
'AcceptedCmpOverall'],
dtype='object')
En este caso las variables dummy son 'marital_Divorced', 'marital_Married','marital_Single', 'marital_Together', 'marital_Widow', el siguiente código permitira convertirla en una sola variable.
df['marital'] = df[['marital_Divorced', 'marital_Married','marital_Single', 'marital_Together', 'marital_Widow']].idxmax(axis=1)
df['marital']
0 marital_Single
1 marital_Single
2 marital_Together
3 marital_Together
4 marital_Married
...
2200 marital_Married
2201 marital_Together
2202 marital_Divorced
2203 marital_Together
2204 marital_Married
Name: marital, Length: 2205, dtype: object
Note
La función idxmax() devuelve el índice de la primera aparición del valor máximo.
Ejercicio
¿Cómo comprobarías que los datos están bien definidos, esto es, que no se repiten valores en las variables dummy?
Quitamos de la variable df[‘marital’] el prefijo ‘marital_’ y lo guardamos en la variable df[‘marital’].
df['marital'].str.replace('marital_', '')
0 Single
1 Single
2 Together
3 Together
4 Married
...
2200 Married
2201 Together
2202 Divorced
2203 Together
2204 Married
Name: marital, Length: 2205, dtype: object
df['marital']=df['marital'].str.replace('marital_', '')
Note
la función .str permite acceder a los métodos de las cadenas de texto y transforma cada elemento de la serie como cadena de texto.
En este caso .replace reemplaza el prefijo ‘marital_’ por un espacio vacío.
Ejercicio
Realiza transformaciones a las cadenas de texto con las siguientes funciones: .lower(), .upper(), .capitalize(), .title(). ¿Qué hace cada una de estas funciones?
df['marital'] = df['marital'].str.lower()
Ya que tenemos una variable categórica, vamos a hacer un análisis de la distribución de los datos.
### Tabla de frecuencias
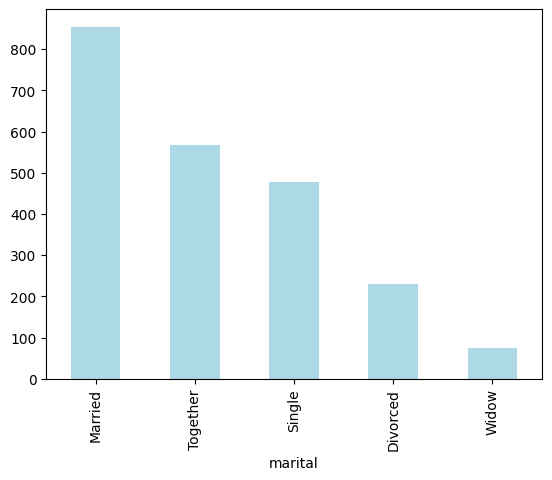
df['marital'].value_counts()
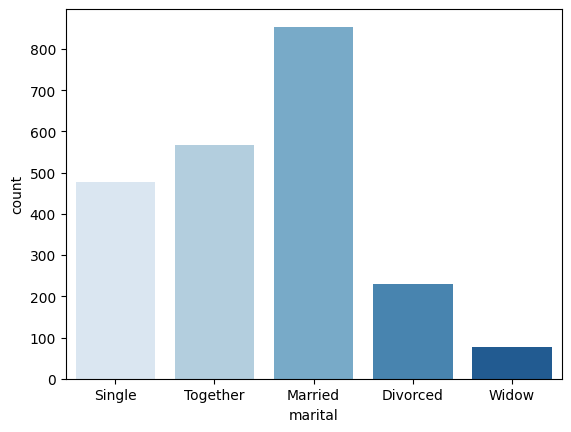
marital
Married 854
Together 568
Single 477
Divorced 230
Widow 76
Name: count, dtype: int64
### Gráfico de barras
df['marital'].value_counts().plot(kind='bar', color='lightblue')
<Axes: xlabel='marital'>
### Otra forma de hacerlo
sns.countplot(x='marital', data=df, palette='Blues')
C:\Users\cizai\AppData\Local\Temp\ipykernel_18176\2871616048.py:3: FutureWarning:
Passing `palette` without assigning `hue` is deprecated and will be removed in v0.14.0. Assign the `x` variable to `hue` and set `legend=False` for the same effect.
sns.countplot(x='marital', data=df, palette='Blues')
<Axes: xlabel='marital', ylabel='count'>
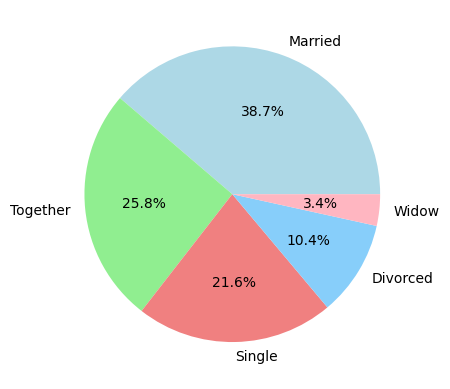
### Gráfico de pastel
df['marital'].value_counts().plot(kind='pie', autopct='%1.1f%%', colors=['lightblue', 'lightgreen', 'lightcoral', 'lightskyblue', 'lightpink'])
<Axes: ylabel='count'>

### Otra forma de hacerlo
plt.pie(df['marital'].value_counts(),
labels=df['marital'].value_counts().index,
autopct='%1.1f%%',
colors=['lightblue', 'lightgreen', 'lightcoral', 'lightskyblue', 'lightpink'])
plt.show()
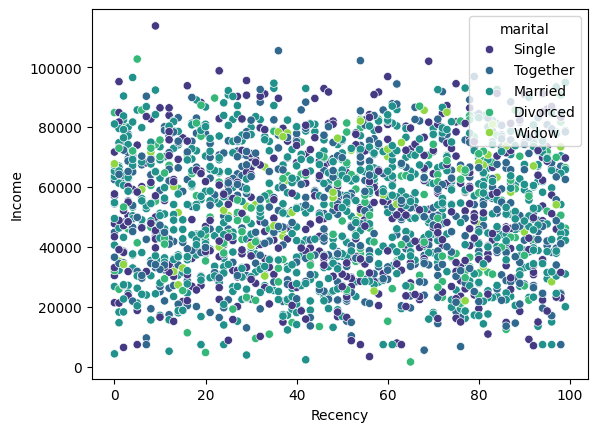
### Scatterplot para tres variables
sns.scatterplot(x='Recency', y='Income', hue='marital', data=df, palette='viridis')
<Axes: xlabel='Recency', ylabel='Income'>
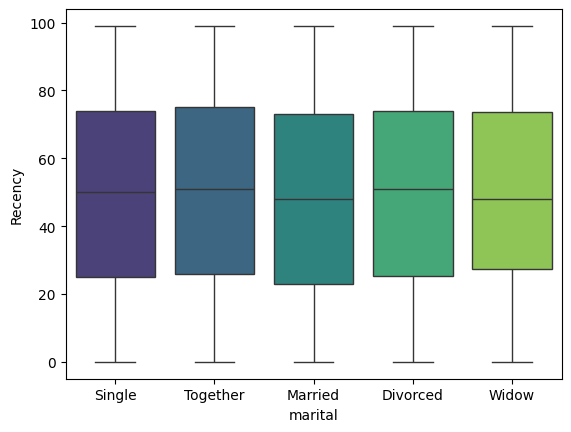
### Boxplot
sns.boxplot(x='marital', y='Recency', data=df, palette='viridis')
C:\Users\cizai\AppData\Local\Temp\ipykernel_18176\3472656058.py:3: FutureWarning:
Passing `palette` without assigning `hue` is deprecated and will be removed in v0.14.0. Assign the `x` variable to `hue` and set `legend=False` for the same effect.
sns.boxplot(x='marital', y='Recency', data=df, palette='viridis')
<Axes: xlabel='marital', ylabel='Recency'>
Cambio dataset#
El dataset que se encuentra en el archivo ifood.csv muestra registros con distribuciones poco probables. Por esta razón, vamos a cambiar el dataset por uno que muestre una distribución más normal.
Note
Recuerda que para cargar los datos debe hacer clic en el panel izquierdo en el botón de exploración de archivos. En ese menu tendra la opción de subir algunos datos. En Google Colab, el archivo se borrará una vez que se cierre el entorno.
El link para descargar el archivo es el siguiente: https://raw.githubusercontent.com/Izainea/mercadeia/master/ifood_simulado.csv
Note
Este dataset se puede cargar directamente desde la web con el siguiente comando:
df = pd.read_csv('https://raw.githubusercontent.com/Izainea/mercadeia/master/ifood_simulado.csv')
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
df_modificado=pd.read_csv("ifood_simulado.csv")
Gráficos de datos numéricos#
Vamos a hacer una exploración de los datos numéricos que se encuentran en el dataset. Para ello, vamos a hacer un análisis de las medidas de tendencia central y dispersión. Así mismo, vamos a hacer un análisis de la distribución de los datos.
## Diferencias entre datasets
## Columnas que no están en el dataset original
df_modificado.columns.difference(df.columns)
Index(['Education_Level', 'Marital_Status'], dtype='object')
## Columnas del dataset original que no están en el dataset modificado
df.columns.difference(df_modificado.columns)
Index(['education_2n Cycle', 'education_Basic', 'education_Graduation',
'education_Master', 'education_PhD', 'marital', 'marital_Divorced',
'marital_Married', 'marital_Single', 'marital_Together',
'marital_Widow'],
dtype='object')
df_modificado
| Marital_Status | Kidhome | Teenhome | Education_Level | Income | Recency | MntWines | MntFruits | MntMeatProducts | MntFishProducts | ... | Customer_Days | MntRegularProds | NumCatalogPurchases | NumDealsPurchases | NumStorePurchases | NumWebPurchases | NumWebVisitsMonth | Response | Z_CostContact | Z_Revenue | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | Single | 0 | 0 | Master | 74927 | 39 | 156 | 17 | 82 | 18 | ... | 566 | 293 | 5 | 2 | 3 | 1 | 4 | 1 | 3 | 11 |
| 1 | Widow | 0 | 0 | Master | 95766 | 22 | 192 | 17 | 101 | 28 | ... | 3103 | 369 | 1 | 7 | 0 | 2 | 2 | 0 | 3 | 11 |
| 2 | Married | 0 | 1 | Graduation | 59676 | 46 | 50 | 7 | 57 | 46 | ... | 565 | 192 | 3 | 6 | 0 | 5 | 6 | 0 | 3 | 11 |
| 3 | Married | 2 | 2 | Graduation | 59663 | 2 | 0 | 39 | 0 | 62 | ... | 1582 | 171 | 4 | 1 | 1 | 2 | 4 | 0 | 3 | 11 |
| 4 | Single | 0 | 0 | Graduation | 66230 | 42 | 152 | 15 | 69 | 20 | ... | 2250 | 268 | 1 | 4 | 5 | 6 | 4 | 0 | 3 | 11 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 10320 | Married | 0 | 1 | Master | 82990 | 35 | 91 | 19 | 73 | 56 | ... | 3960 | 286 | 4 | 3 | 1 | 3 | 1 | 1 | 3 | 11 |
| 10321 | Single | 0 | 0 | Graduation | 82357 | 40 | 155 | 16 | 90 | 23 | ... | 3978 | 306 | 4 | 2 | 1 | 2 | 2 | 0 | 3 | 11 |
| 10322 | Widow | 0 | 0 | Master | 75732 | 80 | 133 | 18 | 69 | 22 | ... | 198 | 266 | 2 | 2 | 1 | 4 | 6 | 0 | 3 | 11 |
| 10323 | Single | 0 | 0 | Graduation | 65084 | 75 | 127 | 7 | 45 | 26 | ... | 3160 | 223 | 6 | 5 | 2 | 1 | 2 | 0 | 3 | 11 |
| 10324 | Single | 0 | 0 | PhD | 60436 | 58 | 122 | 14 | 65 | 26 | ... | 4725 | 239 | 3 | 2 | 2 | 2 | 4 | 0 | 3 | 11 |
10325 rows × 31 columns
### Codigo para explorar el dataset df_modificado
#-- Esto continuará en clase